
Por Paz Pena y Joana Varon
La Inteligencia Artificial (I.A.) es una disciplina que pretende crear máquinas que emulen funciones cognitivas, como el aprendizaje o la resolución de problemas. A diferencia de la inteligencia natural -común en los humanos u otros seres vivos- y que implica conciencia y emociones, la inteligencia «artificial» es desplegada por máquinas a través del procesamiento computacional. Su definición puede incluir una amplia variedad de métodos y herramientas, como el Machine Learning (ML), el reconocimiento facial, el reconocimiento del habla, etc. El ML, en castellano también conocido como aprendizaje automático o aprendizaje de máquinas, es el campo más comúnmente asociado a la IA y se refiere a un método de análisis de datos que automatiza los modelos analíticos mediante la identificación de patrones que dan a las máquinas la capacidad de «aprender» de los datos sin que se les den explícitamente instrucciones sobre cómo hacerlo.
Según el «Algorithmic Accountability Policy Toolkit«, publicado por AINOW, la Inteligencia Artificial debe entenderse como un desarrollo a partir de las prácticas sociales dominantes de ingenieros e informáticos que diseñan los sistemas, la infraestructura industrial y las empresas que gestionan estos sistemas. Por lo tanto, «una definición más completa de la Inteligencia Artificial incluye enfoques técnicos, prácticas sociales y poder industrial.» (AINOW, 2018).
La IA en el sector público
Los sistemas de Inteligencia Artificial se basan en modelos que son representaciones abstractas, universalizaciones y simplificaciones de realidades complejas en las que se omite mucha información según el criterio de sus creadores. Como observa Cathy O’Neil en su libro «Weapons of Math Destruction»: «[L]os modelos, a pesar de su reputación de imparcialidad, reflejan objetivos e ideología. […] Nuestros propios valores y deseos influyen en nuestras elecciones, desde los datos que decidimos recoger hasta las preguntas que formulamos. Los modelos son opiniones incrustadas en las matemáticas». (O’Neil, 2016).
Por lo tanto, los algoritmos son creaciones humanas falibles. Los humanos siempre están presentes en la construcción de los sistemas de decisión automatizados: determinan los objetivos y los usos de los sistemas, son los que determinan qué datos deben recogerse para esos objetivos y usos, ellos recolectan esos datos, deciden cómo entrenar a las personas que utilizan esos sistemas, evalúan el rendimiento del software y, en última instancia, actúan en función de las decisiones y evaluaciones realizadas por los sistemas.
Más concretamente, como plantea Tendayi Achiume, Relatora Especial sobre las formas contemporáneas de racismo, discriminación racial, xenofobia y formas conexas de intolerancia, en su informe «Discriminación racial y nuevas tecnologías digitales», las bases de datos utilizadas en estos sistemas son producto del diseño humano y pueden estar sesgadas de diversas maneras, lo que puede dar lugar -intencionadamente o no- a la discriminación o exclusión de determinadas poblaciones, en particular, de las minorías, por motivos de identidad racial, étnica, religiosa y de género. (Tendayi, 2020).
Ante estos problemas, hay que reconocer que parte de la comunidad técnica ha realizado diversos intentos para definir matemáticamente la «imparcialidad» y, así, cumplir con un estándar demostrable en la materia. Asimismo, varias organizaciones, tanto privadas como públicas, han emprendido esfuerzos para definir normas éticas para la IA. La visualización de datos «Principled Artificial Intelligence» (Berkman Klein, 2020) muestra la diversidad de marcos éticos y basados en los derechos humanos que surgieron de diferentes sectores a partir de 2016 con el objetivo de guiar el desarrollo y el uso de los sistemas de IA. El estudio muestra «un consenso creciente en torno a ocho tendencias temáticas clave: privacidad, responsabilidad, seguridad y protección, transparencia y explicabilidad, imparcialidad y no discriminación, control humano de la tecnología, responsabilidad profesional y promoción de los valores humanos». Sin embargo, como podemos ver en esa lista, ninguno de estos consensos está impulsado por principios de justicia social. En lugar de preguntarnos cómo desarrollar y desplegar un sistema de inteligencia artificial, ¿no deberíamos preguntarnos primero «por qué construirlo», «si es realmente necesario», «a petición de quién», «quién se beneficia», «quién pierde» con el despliegue de un determinado sistema de inteligencia artificial? ¿Debería incluso desarrollarse y desplegarse?
{kind=link}
A pesar de estas interrogantes, muchos Estados de todo el mundo están utilizando cada vez más herramientas algorítmicas de toma de decisiones para determinar la distribución de bienes y servicios, como la educación, los servicios de salud pública, de vigilancia policial, de vivienda, entre otros. Más allá de los principios y de manera más empírica, en Estados Unidos algunos de estos proyectos se han desarrollado más allá de las fases piloto y, frente a la evidencia sobre el sesgo y el daño causado por las decisiones automatizadas, los programas de Inteligencia Artificial han enfrentado críticas en varios frentes. Solo más recientemente, los gobiernos de América Latina están siguiendo la moda de desplegar sistemas de Inteligencia Artificial en los servicios públicos, a veces con el apoyo de empresas estadounidenses que están utilizando la región como un laboratorio de ideas que, tal vez por temor a las críticas en sus países de origen, ni siquiera se prueban en los Estados Unidos primero.
Con el objetivo de construir una caja de herramientas feminista anticolonial para cuestionar estos sistemas desde perspectivas que van más allá de la crítica del Norte Global, a través de una investigación documental y un cuestionario distribuido a través de las redes de derechos digitales en la región, hemos mapeado proyectos donde los sistemas de toma de decisiones algorítmicas están siendo desplegados por los gobiernos con probables implicaciones perjudiciales para la igualdad de género y todas sus interseccionalidades. A diferencia de muchos proyectos y políticas de Inteligencia Artificial que tienden a apartarse del lema de las start-ups «muévete rápido y rompe cosas», nuestra recopilación de casos parte del supuesto: a menos que demuestres lo contrario, si tus objetivos son comunidades marginadas, es muy probable que estés causando daño.
Como resultado, hasta abril de 2021, hemos mapeado 24 casos en Chile, Brasil, Argentina, Colombia y Uruguay, que pudimos clasificar en cinco categorías: sistema judicial, educación, vigilancia policial, prestaciones sociales y salud pública. Varios de ellos se encuentran en una fase temprana de despliegue o se desarrollan como pilotos.
Hasta el momento, hemos llevado a cabo una tarea de análisis de los posibles daños de los programas de Inteligencia Artificial desplegados en las áreas de educación y prestaciones sociales, en Chile, Argentina y Brasil. Como resultado, basándonos tanto en nuestra revisión bibliográfica como en nuestro análisis basado en casos, estamos ampliando gradualmente un esquema basado en casos empíricamente probados para que sirva como uno de los instrumentos de nuestra caja de herramientas anticolonialista. Esperamos que sea un esquema que pueda ayudar a las diversas agendas feministas a plantear preguntas estructurales sobre si un determinado sistema gubernamental de I.A. puede incurrir en posibles perjuicios.
Posibles perjuicios de la toma de decisiones algorítmica desplegada en las políticas públicas
A continuación, presentamos un resumen de las críticas que se están planteando a los sistemas de Inteligencia Artificial desplegados por el sector público, que se cruzan y alimentan entre sí. Sobre la base de una revisión bibliográfica general y también de los hallazgos del análisis basado en casos, se trata de un intento de crear un marco de análisis en proceso que va más allá de los discursos de la I.A. justa, ética o centrada en el ser humano y busca una estructura holística que considere las relaciones de poder para cuestionar la idea de desplegar sistemas de I.A. en varios timones del sector público:
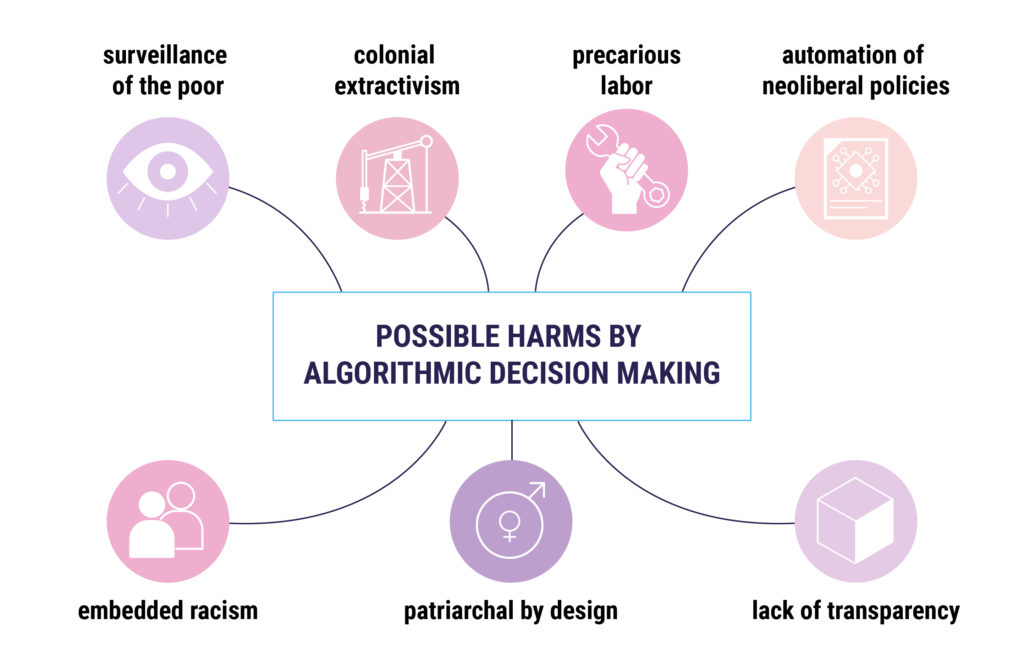
A. Vigilancia de los pobres: convertir la pobreza y la vulnerabilidad en datos legibles por máquinas
El ex relator de Naciones Unidas sobre Extrema Pobreza y Derechos Humanos, Philip Alston, ha criticado el fenómeno en el que «los sistemas de protección y asistencia social están cada vez más impulsados por datos y tecnologías digitales que se utilizan para automatizar, predecir, identificar, vigilar, detectar, focalizar y castigar» (A/74/48037 2019). Estas fuentes de datos granulares permiten a las autoridades inferir los movimientos, las actividades y el comportamiento de las personas, no sin tener implicaciones éticas, políticas y prácticas de cómo el sector público y privado ven y tratan a las personas. Según Linnet Tylor, en su artículo «¿Qué es la justicia de datos?» (Tylor, 2017), esto es aún más desafiante en los casos de porciones de la población con bajos ingresos, ya que la capacidad de las autoridades para recopilar datos estadísticos precisos sobre ellos era previamente limitada, pero ahora están en el punto de mira de los sistemas de clasificaciones regresivas que perfilan, juzgan, castigan y vigilan.
La mayoría de estos programas se aprovechan de la tradición de vigilancia del Estado sobre las poblaciones vulnerables (Eubanks, 2018), convierten su existencia en datos y ahora utilizan algoritmos para determinar la concesión de beneficios sociales por parte de los Estados. Analizando el caso de Estados Unidos, Eubanks muestra cómo el uso del sistema de Inteligencia Artificial se somete a una larga tradición de instituciones que gestionan la pobreza y que buscan a través de estas innovaciones adaptarse y continuar con su afán de contener, vigilar y castigar a los pobres. Por lo tanto, convirtiendo la pobreza y la vulnerabilidad en datos legibles por las máquinas, con consecuencias reales sobre la vida y los medios de subsistencia de los ciudadanos implicados (Masiero, & Das, 2019). Asimismo, Cathy O’Neil (2016), analizando los usos de la IA en Estados Unidos (EEUU), afirma que muchos sistemas de Inteligencia Artificial «tienden a castigar a los pobres», lo que significa que es cada vez más común que las personas ricas se beneficien de las interacciones personales, mientras que los datos de los pobres son procesados por máquinas que toman decisiones sobre sus derechos.
Esto adquiere mayor relevancia si tenemos en cuenta que la clase social tiene un poderoso componente de género. Es habitual que las políticas públicas hablen de la «feminización de la pobreza». De hecho, en la IV Conferencia de las Naciones Unidas sobre la Mujer, celebrada en Pekín en 1995, se afirmó como conclusión que el 70% de los pobres del mundo eran mujeres. Las razones por las que la pobreza afecta a las mujeres no tienen que ver con razones biológicas sino con estructuras de desigualdad social que dificultan la superación de la pobreza por parte de las mujeres, como el acceso a la educación y al empleo (Aguilar, 2011).
B. Racismo incrustado
Para la Relatora Especial de la ONU, E. Tandayi (2020), las tecnologías digitales emergentes también deben entenderse como capaces de crear y mantener la exclusión racial y étnica en términos sistémicos o estructurales. Esto es también lo que los investigadores tecnológicos sobre raza e IA en los Estados Unidos, como Ruha Benjamin, Joy Buolamwini, Timnit Gebru y Safiya Noble destacan en sus estudios de caso, pero también en América Latina, Nina da Hora, Tarzisio Silva y Pablo Nunes, todos de Brasil, lo han señalado al investigar desde las tecnologías de reconocimiento facial a los algoritmos de los motores de búsqueda. Particularmente, Ruha Benjamin (2019) analiza cómo el uso de las nuevas tecnologías refleja y reproduce las injusticias raciales existentes en la sociedad estadounidense, aunque se promuevan y perciban como más objetivas o progresistas que los sistemas discriminatorios de una época anterior. En este sentido, para esta autora, cuando la IA pretende determinar hasta qué punto las personas de todas las clases merecen oportunidades, los diseñadores de estas tecnologías construyen un sistema de castas digital estructurado sobre la discriminación racial existente.
Desde el propio desarrollo tecnológico, Noble (2018) demuestra cómo los buscadores comerciales como Google no solo median, sino que están mediados por una serie de imperativos comerciales que, a su vez, se apoyan en políticas tanto económicas como informativas que acaban avalando la mercantilización de la identidad de las mujeres. En este caso, lo expone analizando una serie de búsquedas en Google en las que las mujeres negras acaban siendo sexualizadas por la información contextual que arroja el buscador (por ejemplo, relacionándolas con mujeres salvajes y sexuales).
Otro estudio notable es el de Buolamwini & Gebru (2018), quienes analizaron tres sistemas comerciales de reconocimiento facial que incluyen la capacidad de clasificar rostros por género. Encontraron que los sistemas exhiben tasas de error más altas para las mujeres de piel más oscura que para cualquier otro grupo, con las tasas de error más bajas para los varones de piel clara. Las autoras atribuyen estos sesgos de raza y género a la composición de los conjuntos de datos utilizados para entrenar estos sistemas, que estaban compuestos en su inmensa mayoría por sujetos de apariencia masculina de piel clara.
C. Patriarcal por diseño: sexismo, heteronormatividad obligatoria y binarismo de género
Muchos sistemas de IA funcionan clasificando a las personas en una visión binaria del género, así como reforzando estereotipos obsoletos de género y orientación sexual. Un estudio reciente, del que es coautor el científico senior de DeepMind Shakir Mohamed, expone cómo el debate sobre la equidad algorítmica ha omitido la orientación sexual y la identidad de género, con impactos concretos en «la censura, el lenguaje, la seguridad en línea, la salud y el empleo» que conducen a la discriminación y la exclusión de las personas LGBT+ (Tomasev et. Al, 2021).
El género se ha analizado de diversas maneras en la Inteligencia Artificial. West, Whittaker y Crawford (2019) argumentan que la crisis de la diversidad en la industria y las cuestiones de sesgo en los sistemas de IA (particularmente la raza y el género) son aspectos interrelacionados del mismo problema. Los investigadores comúnmente examinaron estas cuestiones de forma aislada en el pasado, pero la creciente evidencia muestra que están estrechamente entrelazadas. Sin embargo, advierten, a pesar de todas las pruebas sobre la necesidad de diversidad en los campos tecnológicos, tanto en el ámbito académico como en el industrial, estos indicadores se han estancado.
Inspirados en Buolamwini & Gebru (2018), Silva & Varon (2021) investigaron cómo afectan las tecnologías de reconocimiento facial a las personas transgénero y concluyeron que, aunque los principales organismos públicos de Brasil ya utilizan este tipo de tecnologías para verificar las identidades para acceder a los servicios públicos, existe poca transparencia sobre la precisión de las mismas (rastreando falsos positivos o falsos negativos), así como sobre la privacidad y la protección de datos ante las prácticas de intercambio de datos entre organismos de la administración pública e incluso entre entidades privadas.
En el caso de Venezuela, en medio de una crisis humanitaria sostenida, el Estado ha implementado sistemas biométricos para controlar la adquisición de productos de primera necesidad, lo que ha dado lugar a varias denuncias de discriminación contra extranjeros y transexuales. Según Díaz Hernández (2021), la legislación para proteger a las personas transgénero es prácticamente inexistente. No se les permite el reconocimiento de su identidad, lo que hace que esta tecnología resignifique el valor de sus cuerpos «y los convierte en cuerpos inválidos, que por lo tanto quedan al margen del sistema y de la sociedad» (p.12).
En el caso de los programas de gestión de la pobreza a través de los sistemas de big data e Inteligencia Artificial, es crucial observar cómo las mujeres pobres son particularmente objeto de vigilancia por parte de los Estados y cómo esto lleva a la reproducción de las desigualdades económicas y de género (Castro & López, 2021).
D. El extractivismo colonial de los cuerpos y territorios de datos
Autores como Couldry y Mejías (2018) y Shoshana Zuboff (2019) revisan el estado actual del capitalismo donde la producción y extracción de datos personales naturalizan la apropiación colonial de la vida en general. Para ello, operan una serie de procesos ideológicos donde, por un lado, los datos personales son tratados como materia prima, naturalmente desechable para la expropiación del capital y, por otro, donde las corporaciones son consideradas las únicas capaces de procesar y, por tanto, apropiarse de los datos.
En cuanto al colonialismo y la Inteligencia Artificial, Mohamed et al. (2020) examinan cómo la colonialidad se presenta en los sistemas algorítmicos a través de la opresión algorítmica institucionalizada (la subordinación injusta de un grupo social a expensas del privilegio de otro), la explotación algorítmica (las formas en que los actores institucionales y las corporaciones se aprovechan de personas a menudo ya marginadas para el beneficio asimétrico de estas industrias) y la desposesión algorítmica (la centralización del poder en unos pocos y la desposesión de muchos), en un análisis que busca destacar las continuidades históricas de las relaciones de poder.
Crawford (2021) demanda una visión más amplia de la Inteligencia Artificial como forma crítica de entender que estos sistemas dependen de la explotación: por un lado, de los recursos energéticos y minerales, de la mano de obra barata y, además, de nuestros datos a escala. En otras palabras, la IA es una industria extractiva.
Todos estos sistemas son intensivos en energía y dependen en gran medida de la extracción de minerales. Sólo en América Latina, tenemos el triángulo del litio dentro de Argentina, Bolivia y Chile, así como varios yacimientos de minerales 3TG (estaño, tungsteno, tantalio y oro) en la región del Amazonas, todos ellos minerales utilizados en dispositivos electrónicos de vanguardia. Como plantean Danae Tapia y Paz Peña, las comunicaciones digitales se basan en la explotación, aunque «los análisis sociotécnicos del impacto ecológico de las tecnologías digitales son casi inexistentes en la comunidad hegemónica de derechos humanos que trabaja en el contexto digital» (Tapia & Peña, 2021). Y, aún más allá del impacto ecológico, Camila Nobrega y Joana Varon también exponen, las narrativas de la economía verde junto con los tecnosolucionismos están «amenazando múltiples formas de existencia, de usos históricos y de gestión colectiva de los territorios», no por casualidad las autoras descubrieron que Alphabet Inc, empresa matriz de Google está explotando minerales 3TG en regiones de la Amazonía donde hay un conflicto de tierras con los indígenas (Nobrega & Varon, 2021).
E. Automatización de las políticas neoliberales
Tal y como lo enmarca Payal Arora (2016), los discursos en torno al big data tienen una connotación abrumadoramente positiva gracias a la idea neoliberal de que la explotación con fines de lucro de los datos de los pobres por parte de las empresas privadas sólo beneficiará a la población. Desde un punto de vista económico, los estados de bienestar digitales están profundamente entrelazados con la lógica del mercado capitalista y, en particular, con las doctrinas neoliberales que buscan profundas reducciones del presupuesto general de bienestar, incluyendo el número de beneficiarios, la eliminación de algunos servicios, la introducción de formas exigentes e intrusivas de condicionalidad de las prestaciones, hasta el punto que los individuos no se ven a sí mismos como sujetos de derechos sino como solicitantes de servicios (Alston, 2019, Masiero y Das, 2019). En este sentido, es interesante ver que los sistemas de AI, en sus esfuerzos neoliberales por focalizar los recursos públicos, también clasifican quién es el sujeto pobre a través de mecanismos automatizados de exclusión e inclusión (López, 2020).
F. Trabajo precario
Centrados especialmente en la Inteligencia Artificial y los algoritmos de las empresas Big Tech, la antropóloga Mary Gray y el informático Siddharth Suri señalan el «trabajo fantasma» o invisible que impulsa las tecnologías digitales. Etiquetar imágenes, limpiar bases de datos, son trabajos manuales que se realizan muy a menudo en condiciones laborales indeseables «para que Internet parezca inteligente». Las condiciones laborales de estos trabajos son muy precarias, normalmente marcadas por el exceso mal pagado de trabajo, sin beneficios sociales ni estabilidad, muy diferentes de las condiciones laborales de los creadores de dichos sistemas (Crawford, 2021). ¿Quién cuida su base de datos? Como siempre, el trabajo de cuidado no es reconocido como un trabajo valioso.
G.Falta de transparencia
Según AINOW (2018), cuando las agencias gubernamentales adoptan herramientas algorítmicas sin la adecuada transparencia, responsabilidad y supervisión externa, su uso puede amenazar las libertades civiles y exacerbar los problemas existentes en las agencias gubernamentales. En la misma línea, la OCDE (Berryhill et al., 2019) postula que la transparencia es estratégica para fomentar la confianza del público en la herramienta.
Los puntos de vista más críticos comentan el enfoque neoliberal cuando la transparencia depende de la responsabilidad de los individuos, ya que no tienen el tiempo o el deseo de comprometerse con formas más significativas de transparencia y consentimiento en línea (Annany & Crawford, 2018). Por lo tanto, los intermediarios gubernamentales con especial comprensión e independencia deberían desempeñar un papel aquí (Brevini & Pasquale, 2020). Además, Annany & Crawford (2018) sugieren que lo que hace la visión actual de la transparencia en la IA es fetichizar el objeto de la tecnología, sin entender que la tecnología es un ensamblaje de actores humanos y no humanos, por lo tanto, para entender el funcionamiento de la IA es necesario ir más allá de mirar el mero objeto.
Análisis basado en casos:
Más allá de las destacadas compañeras antirracistas y feministas que se centran en el despliegue de los sistemas de IA en Estados Unidos, queremos contribuir construyendo lentes feministas para cuestionar el sistema de IA basadas en nuestras experiencias latinoamericanas e inspiradas en las teorías feministas decoloniales, de ahí que en el siguiente post nos centremos en analizar casos de América Latina con estas lentes:
a) Sistema Alerta Niñez – SAN, Chile
b) Plataforma Tecnológica de Intervención Social / Projeto Horus – Argentina y Brasil
Bibliografia
Aguilar, P. L. (2011). La feminización de la pobreza: conceptualizaciones actuales y potencialidades analíticas. Revista Katálysis, 14(1),126-133
AINOW. 2018. Algorithmic Accountability Policy Toolkit. https://ainowinstitute.org/aap-toolkit.pdf
Alston, Philip. 2019. Report of the Special rapporteur on extreme poverty and human rights. Promotion and protection of human rights: Human rights questions, including alternative approaches for improving the effective enjoyment of human rights and fundamental freedoms. A/74/48037. Seventy-fourth session. Item 72(b) of the provisional agenda.
Ananny, M., & Crawford, K. (2018). Seeing without knowing: Limitations of the transparency ideal and its application to algorithmic accountability. New Media & Society, 20(3), 973–989. https://doi.org/10.1177/1461444816676645
Arora, P. (2016). The Bottom of the Data Pyramid: Big Data and the Global South. International Journal of Communication, 10, 1681-1699.
Benjamin, R. (2019). Race after technology: Abolitionist tools for the new Jim code. Polity.
Berryhill, J., Kok Heang, K., Clogher, R. & McBride, K. (2019). Hello, World: Artificial Intelligence and its Use in the Public Sector. OECD.
Brevini, B., & Pasquale, F. (2020). Revisiting the Black Box Society by rethinking the political economy of big data. Big Data & Society. https://doi.org/10.1177/2053951720935146
Bridle, J. (2018). New Dark Age: Technology, Knowledge and the End of the Future. Verso Books.
Bright, J., Bharath, G., Seidelin, C., & Vogl, T. M. (2019). Data Science for Local Government (April 11, 2019). Available at SSRN: https://ssrn.com/abstract=3370217 or http://dx.doi.org/10.2139/ssrn.3370217
Buolamwini, J. & Gebru, T. (2018). Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. Proceedings of the 1st Conference on Fairness, Accountability and Transparency, in PMLR 81:77-91Castro, L. & López, J. (2021). Vigilanco a las “buenas madres”. Aportes desde una perspectiva feminista para la investigación sobre la datificación y la vigilancia en la política social desde Familias En Acción. Fundación Karisma. Colombia.
Couldry, N., & Mejias, U. (2019). Data colonialism: rethinking big data’s relation to the contemporary subject. Television and New Media, 20(4), 336-349.
Crawford, K. (2021). Atlas of AI. Power, Politics, and the Planetary Costs of Artificial Intelligence. Yale University Press.
Díaz Hernández, M. (2020) Sistemas de protección social en Venezuela: vigilancia, género y derechos humanos. In Sistemas de identificación y protección social en Venezuela y Bolivia. Impactos de género y otros tipos de discriminación. Derechos Digitales.
Eubanks, V. (2018). Automating inequality: how high-tech tools profile, police, and punish the poor. First edition. New York, NY: St. Martin’s Press.
López, J. (2020). Experimentando con la pobreza: el SISBÉN y los proyectos de analítica de datos en Colombia. Fundación Karisma. Colombia.
Masiero, S., & Das, S. (2019). Datafying anti-poverty programmes: implications for data justice. Information, Communication & Society, 22(7), 916-933.
Mohamed, S., M. Png & W. Isaac. (2020). Decolonial AI: Decolonial Theory as Sociotechnical Foresight in Artificial Intelligence. Philosophy & Technology. https://doi.org/10.1007/s13347-020-00405-8
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York University Press.
Nobrega, C; Varon, J. (2021). Big tech goes green(washing): feminist lenses to unveil new tools in the master’s house. Giswatch, APC. Available at: https://www.giswatch.org/node/6254
O’Neil, C. (2016). Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. New York: Crown.
Silva M.R. & Varon, J. (2021). Reconhecimento facial no setor público e identidades trans: tecnopolíticas de controle e ameaça à diversidade de gênero em suas interseccionalidades de raça, classe e território. Coding Rights.
Taylor, L. (2017). What is data justice? The case for connecting digital rights and freedoms globally. Big Data & Society, July-December, 1-14. https://journals.sagepub.com/doi/10.1177/2053951717736335
Tapia, D; Peña. P. (2021). White gold, digital destruction: Research and awareness on the human rights implications of the extraction of lithium perpetrated by the tech industry in Latin American ecosystems. Giswatch, APC. Available at: https://www.giswatch.org/node/6247
Tendayi Achiume, E. (2020). Racial discrimination and emerging digital technologies: a human rights analysis. Report of the Special Rapporteur on contemporary forms of racism, racial discrimination, xenophobia and related intolerance. A/HRC/44/57. Human Rights Council. Forty-fourth session. 15 June–3 July 2020.
West, S.M., Whittaker, M. and Crawford, K. (2019). Discriminating Systems: Gender, Race and Power in AI. AI Now Institute.
Zuboff, S. (2019). The age of surveillance capitalism: the fight for a human future at the new frontier of power. Profile Books.